04/ 9 — 光譜指紋 + 預處理
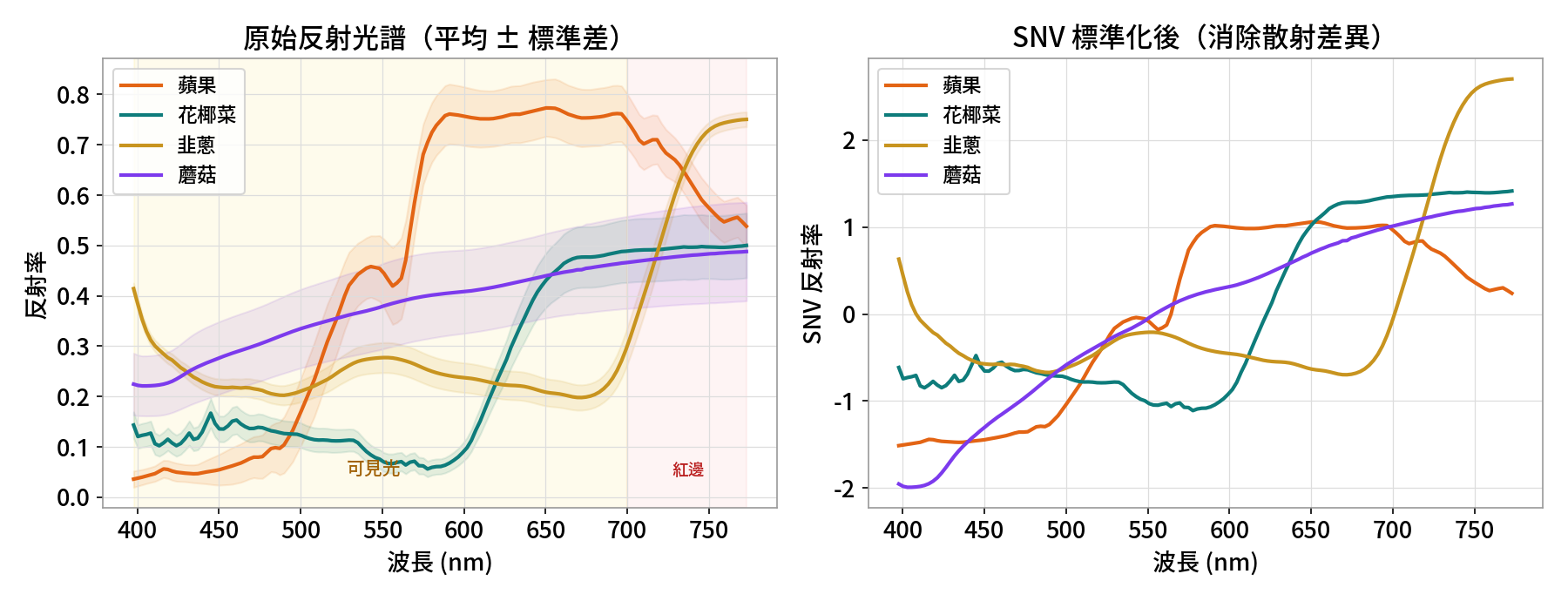
左:四食材原始反射光譜(平均±標準差),形狀各異=指紋。 右:SNV 標準常態變量標準化後,消除表面散射、量測距離造成的平移,凸顯真正的化學差異。
05/ 9 — 降維 PCA
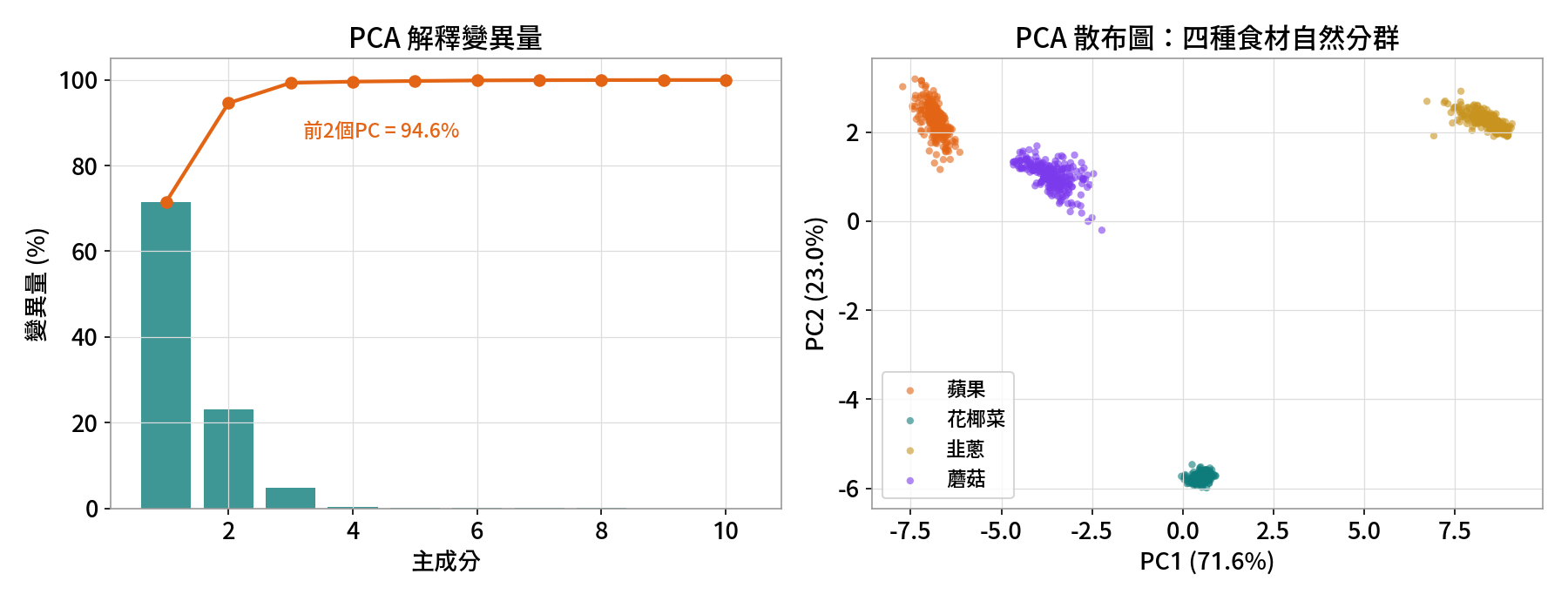
141 個波段高度相關。主成分分析 PCA 後,前兩個主成分就抓住 94.6% 變異。把 PC1-PC2 畫成散布圖,四種食材自動分成四群——還沒分類,資料自己就攤牌了。
06/ 9 — 分類 SVM
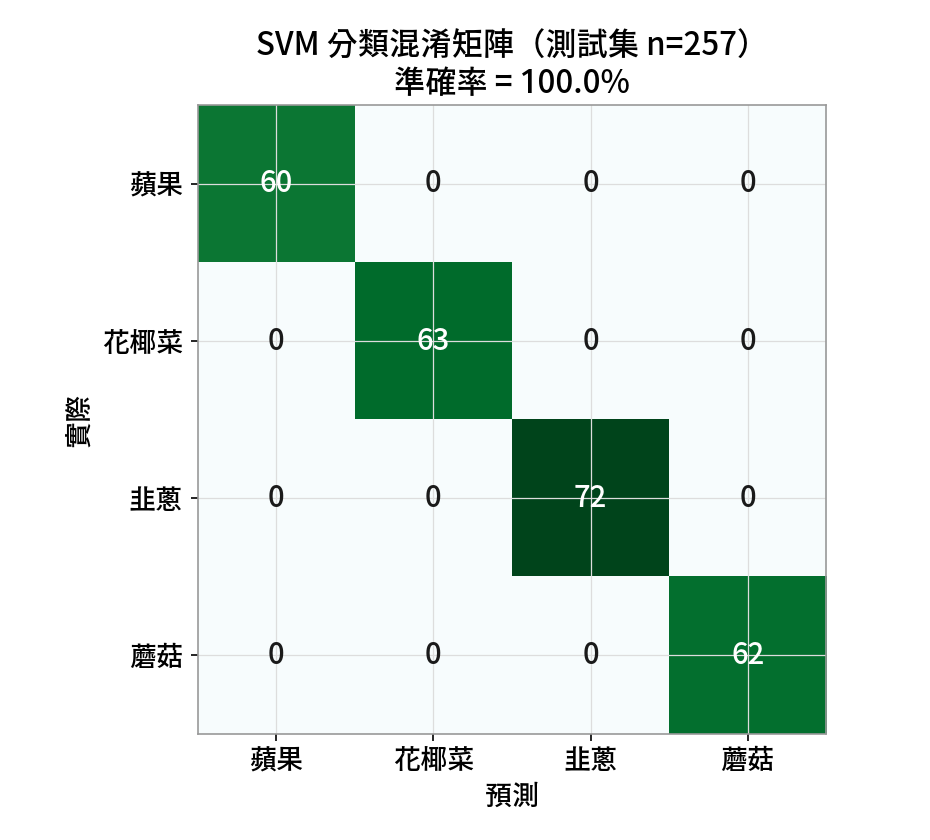
SVM / 隨機森林
100%測試集 257 筆,對角線全中、零誤分。
⚠️ 別急著高興:四種食材差異這麼大,100% 代表這題太簡單了。
真正困難、更有價值的,是下一個任務——定量預測。
07/ 9 — 迴歸 PLS(真功夫)
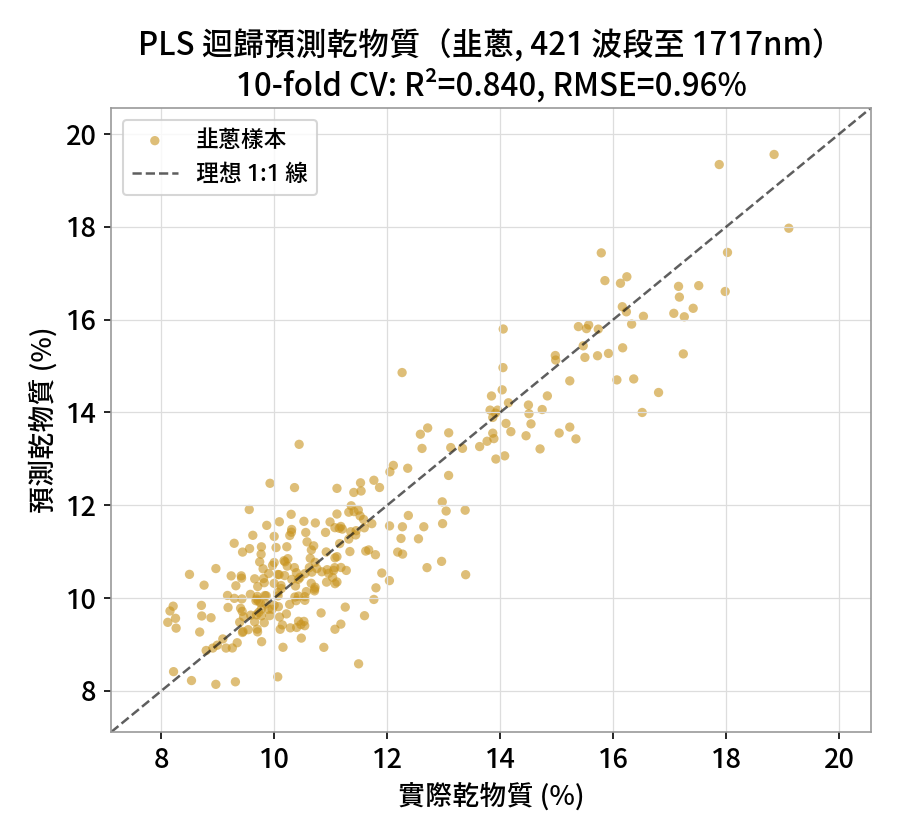
PLS 偏最小平方迴歸
R²=0.84韭蔥完整光譜(含 NIR 至 1717nm),10-fold 交叉驗證,RMSE 僅 0.96%。
定性「是哪種」容易;定量「含多少」才難。
近紅外能感應水分與有機物吸收——這正是真實食品品管在用的技術。