最貼近分子細節的量測工具
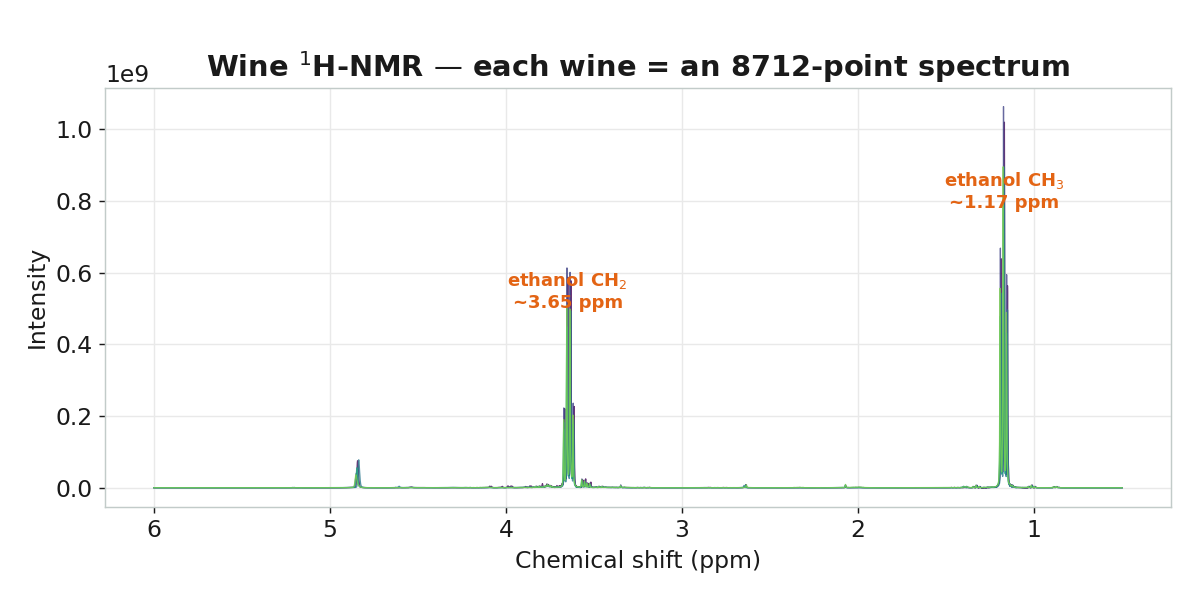
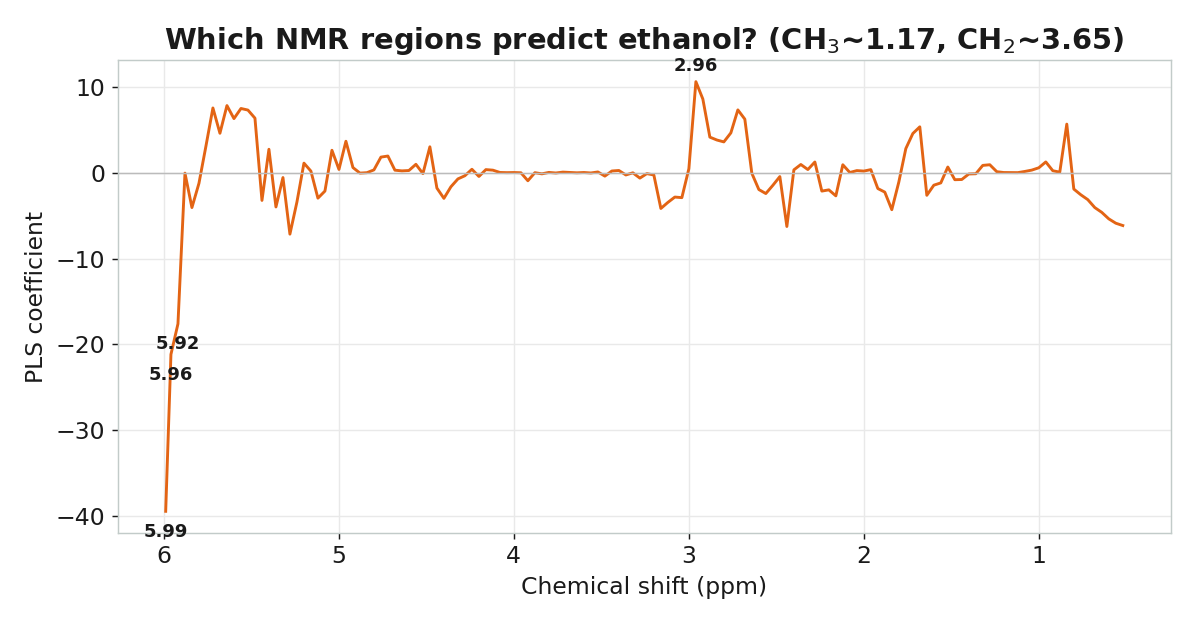
核磁共振(Nuclear Magnetic Resonance, ¹H-NMR)依氫核所處的化學環境,輸出對應化學位移(ppm)的訊號強度。不同化合物在固定的 ppm 位置出現——乙醇在 1.17 / 3.65 ppm,蘋果酸在 ~2.96 ppm。一次量測,即可拿到食品樣本的完整化學指紋,而不需事先指定量什麼成分。
非破壞性
樣品可回收,量測快速(分鐘級),適合批次品質控管。化學位移指紋
每種分子在固定 ppm 出現,一條光譜包含上百種成分資訊。但是…
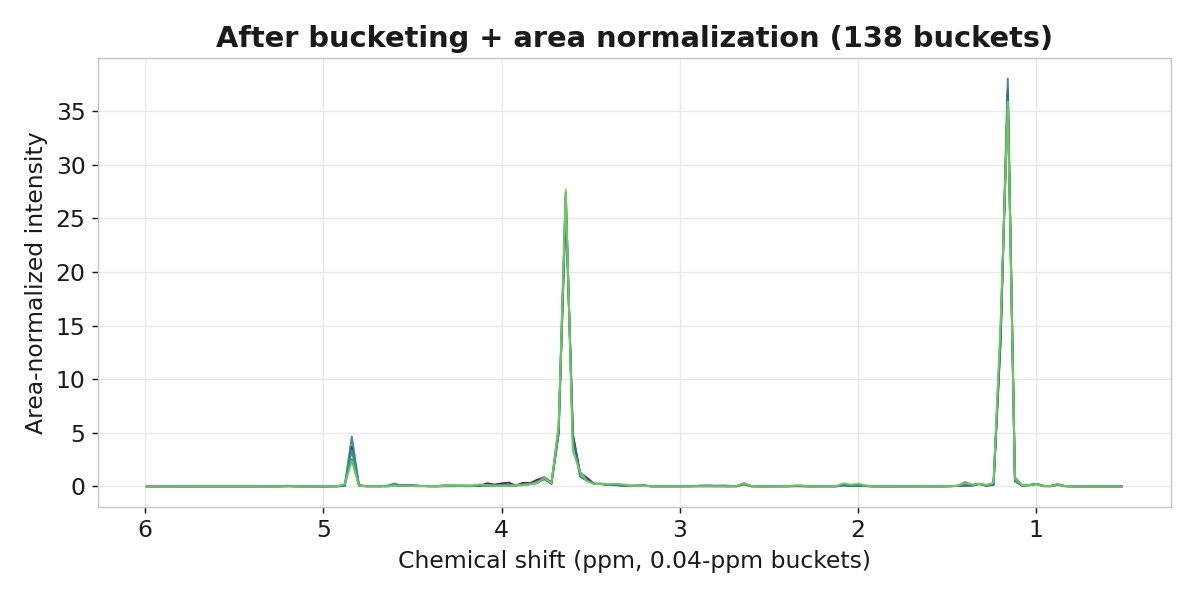
一條光譜是 8712 個 ppm 點,必須靠化學計量學才能從中提取含量與結構資訊。酒樣本 ──▶ ¹H-NMR 量測 ──▶ 8712 個 ppm 點光譜 ──▶ bucketing → 138 桶 ──▶ 面積標準化 ──▶ PCA / PLS
白酒 ¹H-NMR(公開資料)
KU Quality & Technology(ucphchemometrics.com)公開的 Wine NMR 資料:40 支白酒,以 ¹H-NMR 量得從 6.0 ppm 到 0.5 ppm 共 8712 個點的光譜,並附有包含蘋果酸在內的 17 項化學參考值。屬公開學術資料。
前處理:bucketing + 面積標準化
¹H-NMR 光譜的 8712 個點,彼此高度相關且峰位可能有輕微偏移。先做 bucketing:把每 0.04 ppm 寬的區段合併成一個桶,共得 138 個桶——消除偏移、降維。再做 面積標準化(每支酒的桶加總縮放為 100),消除因樣品稀釋濃度不同帶來的整體強度差異。最後做 mean-centering,讓每個桶以自身均值為基準。
| 項目 | 數值 | 說明 |
|---|---|---|
| 樣本數 | 40 | 白酒 |
| 原始 ppm 點 | 8712 | 6.0–0.5 ppm |
| 分桶後維度 | 138 | 0.04 ppm / 桶 |
| PLS 目標值 | 蘋果酸 malicAcid | 0.04–3.12 g/L(連續值) |
| 參考值數量 | 17 項 | 乙醇、甘油、有機酸、pH 等 |
PCA:把 8712 個 ppm 點壓成幾個方向
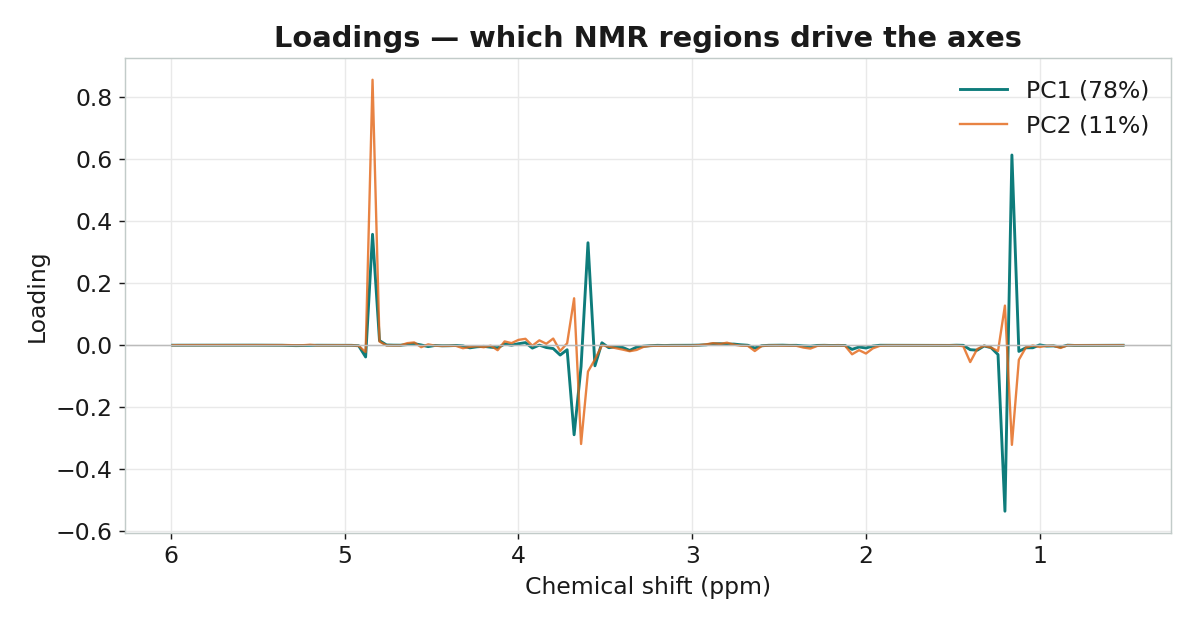
主成分分析(Principal Component Analysis)在資料最分散的方向上建立新座標軸: PC1 是變異最大的方向、PC2 與它垂直且次大……少數幾個主成分,就能描述最重要的化學結構。
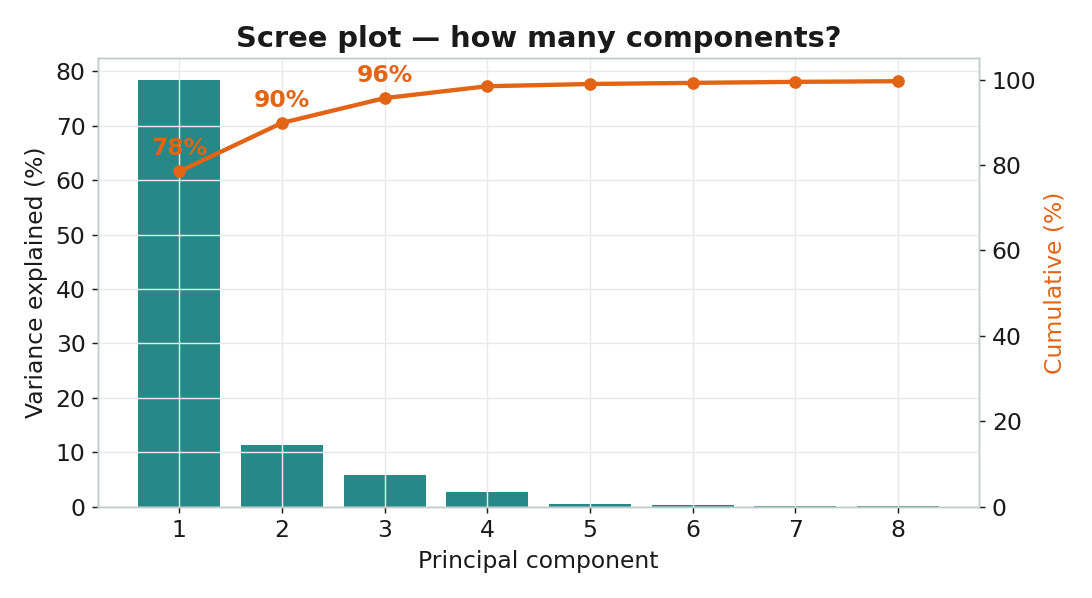
要保留幾個主成分?
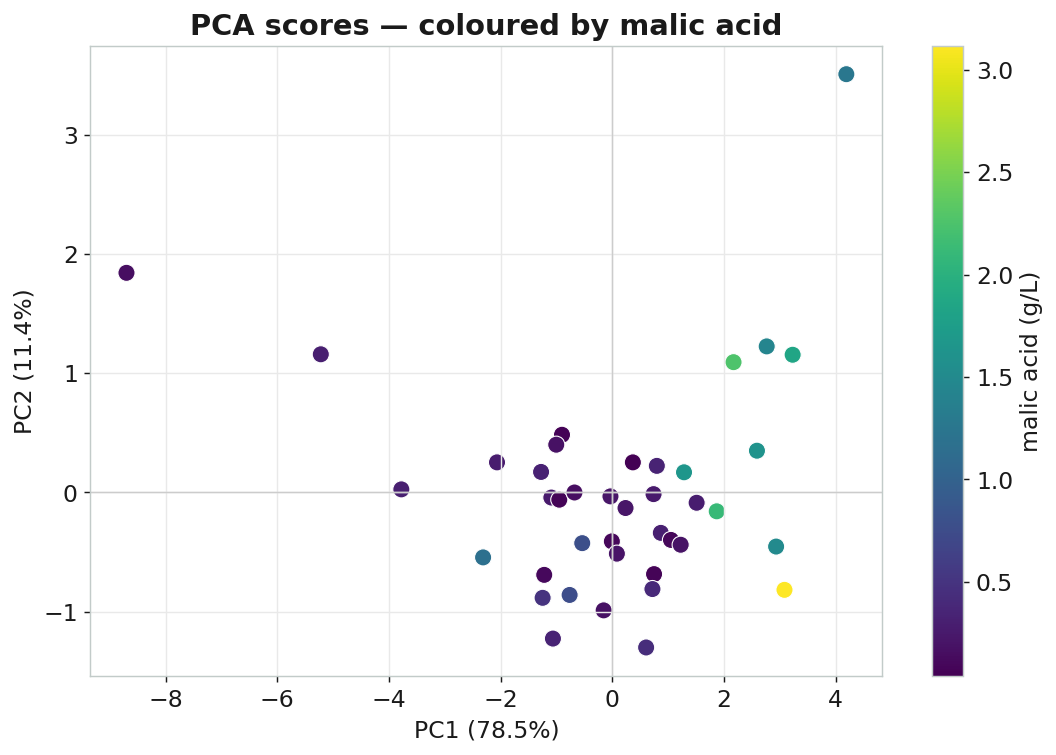
分數圖:依蘋果酸濃度著色
負荷量回連 ppm 化學區
PLS 回歸:用光譜「定量」蘋果酸含量
偏最小二乘回歸(Partial Least Squares Regression)給模型看過蘋果酸含量的標準值,找出的潛在變量 同時解釋光譜的變異、又對齊目標含量的梯度。這就是它和 PCA 的關鍵差異:PCA 只看 X,PLS 一手抓 X、一手抓連續目標 y。
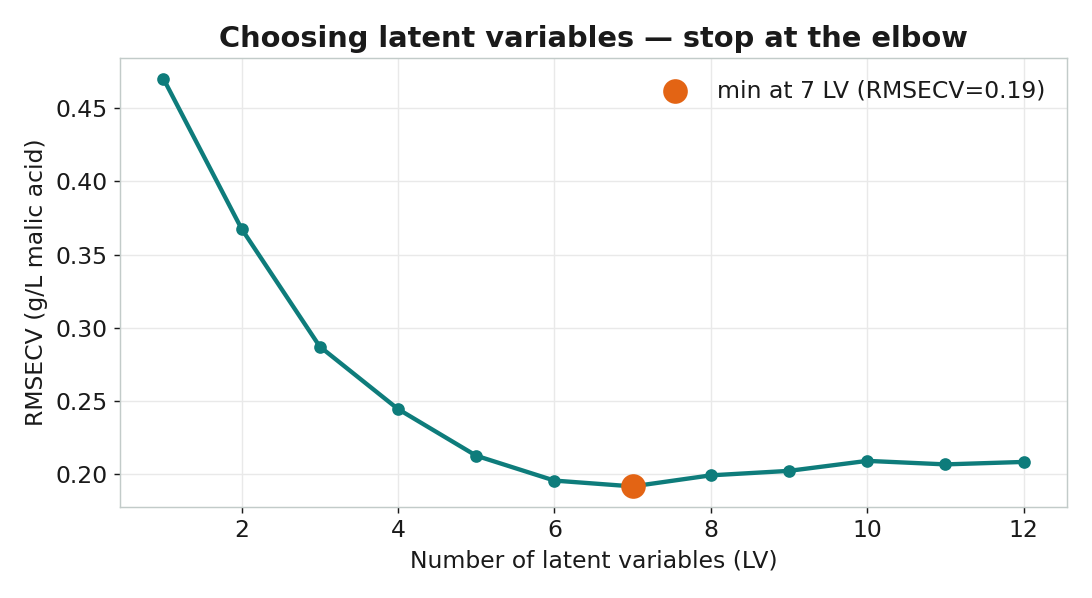
選幾個潛在變量?用交叉驗證 RMSECV
成果:預測 vs 真實(交叉驗證)
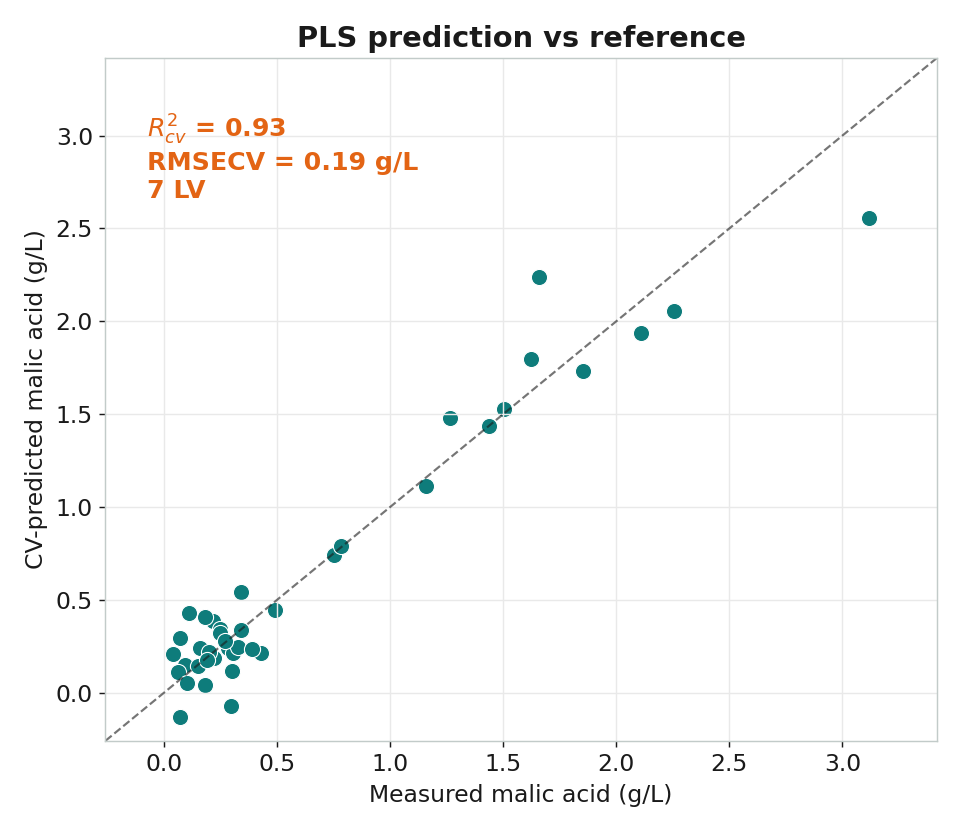
R²cv = 0.93
交叉驗證,93% 的蘋果酸變異可由 NMR 解釋。7 個 LV
RMSECV 在此達到轉折最低,夠用就好。哪些 ppm 在預測蘋果酸?
Python 程式(scikit-learn)
整套分析用 numpy / pandas / scipy / scikit-learn 完成,可重現。完整檔案見 python/ 目錄。
前處理 — bucketing + 面積標準化(python/nmr_utils.py)
def bucket(X, ppm, width=0.04):
"""Sum NMR intensities into width-ppm bins (standard NMR bucketing)."""
edges = np.arange(ppm.min(), ppm.max() + width, width)
idx = np.digitize(ppm, edges)
cols = []
for b in range(1, len(edges)):
sel = idx == b
if sel.sum(): cols.append(X[:, sel].sum(1))
return np.array(cols).T # shape (n_samples, n_buckets)
def preprocess(Xb):
"""Area normalization — remove dilution effect, x100."""
Xv = np.asarray(Xb, float)
tot = Xv.sum(1, keepdims=True); tot[tot == 0] = 1.0
return Xv / tot * 100.0PCA — 主成分分析(python/02_pca.py)
from sklearn.decomposition import PCA
meta, Xb, ctr = load()
Xp = preprocess(Xb.values)
Xc = Xp - Xp.mean(0) # mean-centering
pca = PCA(n_components=8).fit(Xc)
T = pca.transform(Xc) # scores: each wine's position
# evr[0] = 78.5% (PC1 dominates — ethanol structure)
# top 3 PCs cumulate 95.7% variancePLS 回歸 — 預測蘋果酸含量(python/03_pls.py)
from sklearn.cross_decomposition import PLSRegression
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import StandardScaler, FunctionTransformer
from sklearn.model_selection import KFold, cross_val_predict
from sklearn.metrics import r2_score, mean_squared_error
y = meta["malicAcid"].values.astype(float) # 連續目標:蘋果酸 g/L
def pipe(k):
return Pipeline([("norm", FunctionTransformer(preprocess)),
("center", StandardScaler(with_std=False)),
("pls", PLSRegression(n_components=k))])
cv = KFold(10, shuffle=True, random_state=42)
# best_k = 7 LV -> RMSECV = 0.19 g/L, R²cv = 0.93
yhat = cross_val_predict(pipe(7), Xb.values, y, cv=cv).ravel()▶ 如何在本機重跑
pip install numpy pandas scipy scikit-learn matplotlib
cd python
python 01_explore.py # NMR 原始光譜 + bucketing 圖(nm01, nm02)
python 02_pca.py # 陡坡 / 分數 / 負荷量(nm03, nm04, nm05)
python 03_pls.py # RMSECV / 預測 vs 真實 / 係數(nm06, nm07, nm08)
# 所有圖輸出到 python/figures/用 Orange Data Mining 親手拉一遍
課堂可用 Orange 的拖拉式 widget,不寫一行程式就重現上面的 PCA 與 PLS 回歸結果。
開啟 orange/wine_nmr_workflow.ows,把 File 指向 data/wine_nmr_orange.tab 即可。
┌─ Data Table (檢視分桶後光譜)
│
File ────┼─ PCA ──Transformed Data──▶ Scatter Plot ← PCA 分支(Color = malicAcid)
(wine_ │
nmr_ └─ PLS ──▶ Test and Score ──▶ Predictions ──▶ Scatter Plot
orange) (R²/RMSE) (predicted vs malicAcid)關於 Orange PLS widget:Orange 的 PLS widget(Orange.widgets.model.owpls.OWPLS)做的正是數值回歸——和本課的 PLS 回歸完全對應。把 malicAcid 設成 target(連續值),直接用 PLS widget 即可輸出 R²/RMSE,不需任何替代方案。
| 對應概念 | Python 圖 | Orange widget |
|---|---|---|
| NMR 原始光譜 | nm01 | File → Data Table |
| 主成分數量 | nm03 | PCA 視窗內變異曲線 |
| 分數圖(依蘋果酸上色) | nm04 | PCA → Scatter Plot(Color=malicAcid) |
| 選 LV / RMSECV | nm06 | PLS widget 的 Components 參數 + Test&Score RMSE |
| 預測 vs 真實 | nm07 | PLS Model → Predictions → Scatter Plot(x=malicAcid, y=predicted) |
| 哪些 ppm 在預測 | nm08 | PLS widget 的 Coefficients 輸出 |
PCA 與 PLS 回歸,一張表看懂
| 面向 | PCA | PLS 回歸 |
|---|---|---|
| 學習方式 | 非監督(只看 X) | 監督回歸(用 X 與連續目標 y) |
| 目的 | 探索結構、看化學分佈 | 定量預測(蘋果酸、乙醇…) |
| 找方向的準則 | 最大化 X 的變異 | 最大化 X 與目標 y 的共變異 |
| 本課結果 | PC1=78.5%,前 3 個佔 95.7% | 7 LV,R²cv=0.93,RMSECV=0.19 g/L |
| 關鍵圖 | 陡坡圖、分數圖、負荷量 | RMSECV 曲線、預測 vs 真實、係數圖 |
| 何時用 | 先用它「看」資料化學結構 | 確定要定量時用它建模 |