一個樣品,不是一條光譜,而是一張螢光地圖
激發–放射矩陣(Excitation-Emission Matrix, EEM)同時掃描「用哪個波長照」與「樣品放出哪個波長的光」, 得到一張二維螢光指紋。橄欖油裡天然就有會發螢光的成分——生育酚(維生素 E)、葉綠素、氧化產物, EEM 一次就把它們的整體輪廓拍下來。
靈敏
螢光對微量螢光物極敏感,適合追蹤抗氧化劑消耗與氧化產物生成。二維指紋
不預設找誰,一次拍下整個激發 × 放射平面的螢光輪廓。但是…
一張 EEM 是上百個彼此相關的數字,必須靠化學計量學才能解讀。橄欖油樣品 ──▶ 螢光光譜儀掃描(激發 × 放射) ──▶ 每個激發波長一條放射光譜 ──▶ 疊成「激發 × 放射」EEM 矩陣
橄欖油加速老化 EEM(公開資料)
資料來自 Mendeley Data 的 橄欖油老化螢光與 UV 光譜資料集(Venturini、Fluri & Baumgartner): 24 款市售特級初榨橄欖油,經 10 個加速老化階段(Aging Step 0–9),每個樣品量得一張 EEM 螢光指紋。屬公開資料(CC BY 4.0)。
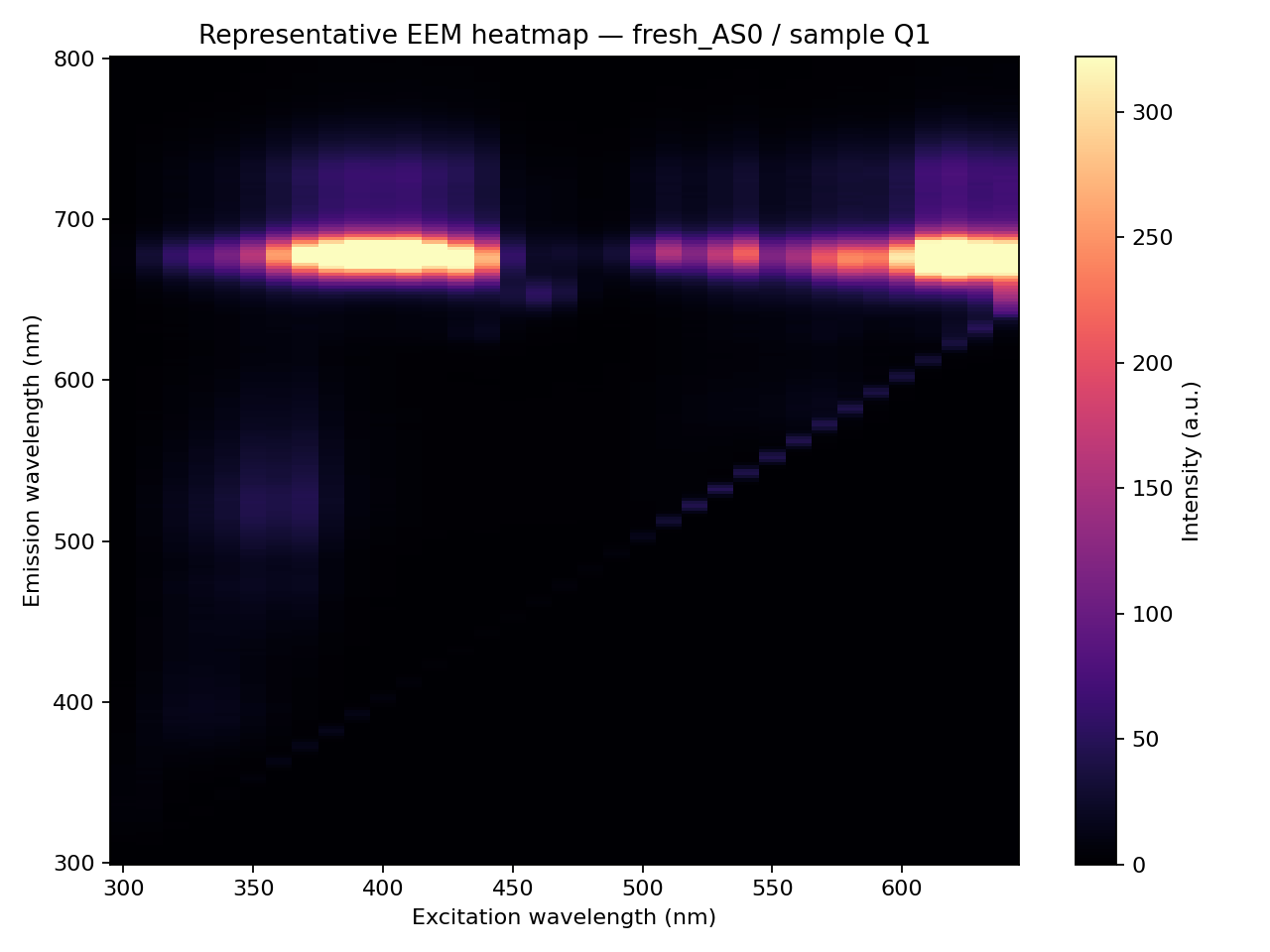
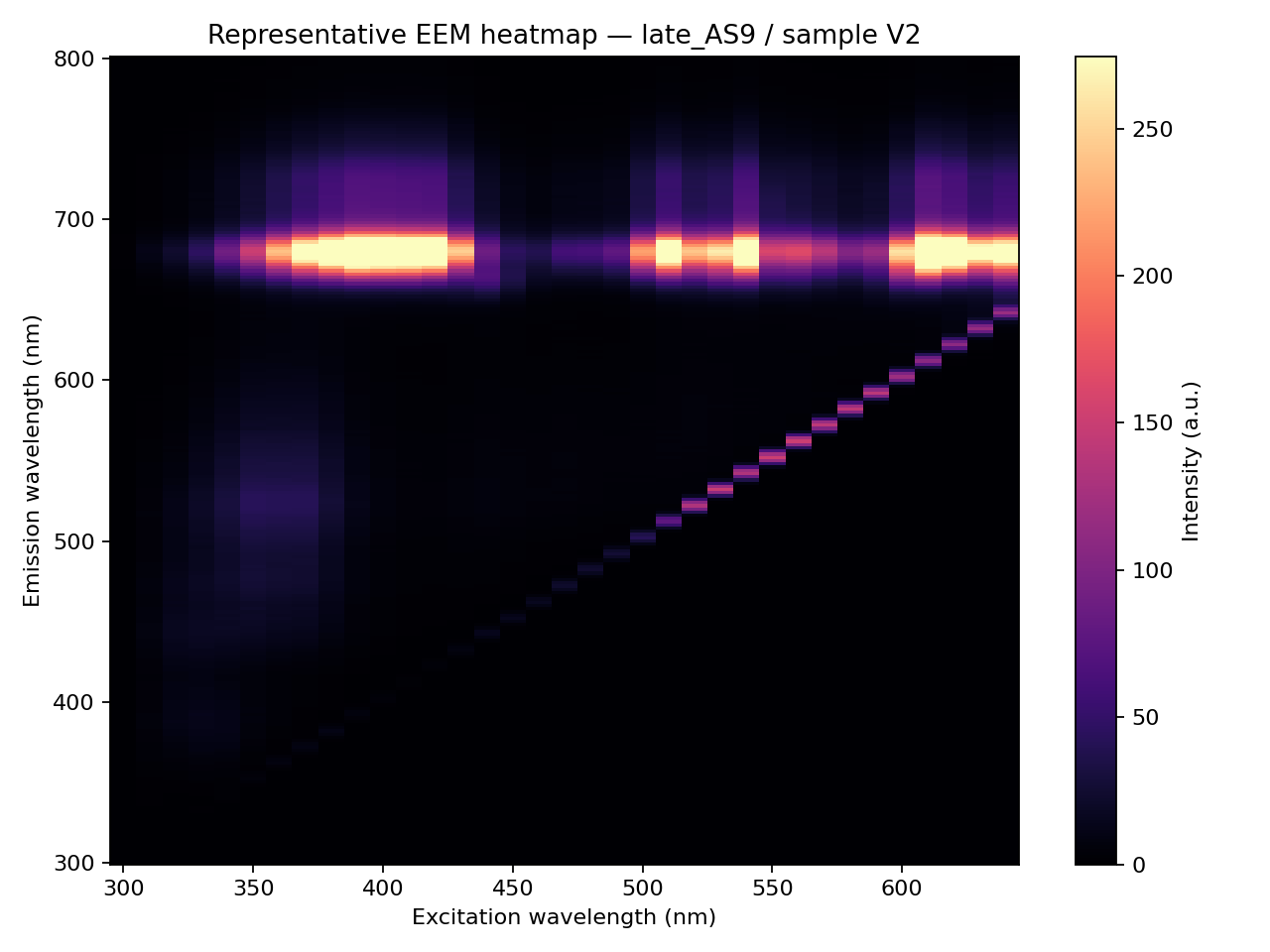
圖中由左下往右上的對角亮線是散射(Rayleigh / Raman),屬光學假訊號、與化學無關;判讀時要避開它,只看真正的螢光亮區。 Python 解析後,每一列代表一個橄欖油 EEM 量測,欄位是分箱(binned)後的螢光特徵與幾個連回化學的區域特徵。
| 老化等級 aging_class | 量測數 | 本課用途 |
|---|---|---|
| fresh(Aging Step 0–2) | 144 | 分類類別 A |
| mid-aged(Aging Step 3–6) | 296 | 分類類別 B |
| late-aged(Aging Step 7–9) | 288 | 分類類別 C |
| 合計 | 728 | PCA 探索 + 監督分類 |
前處理:補值 + 標準化
不同樣品、不同批次的整體強度會有高低差異。先 補值(Impute) 處理缺漏,再 標準化(Normalize / autoscale) 讓每個螢光特徵站上同一起跑點,避免少數高強度區域主導後續的 PCA 與分類——作用等同近紅外光譜裡的 SNV、質譜代謝體裡的 log + autoscale。
把螢光區域連回橄欖油的化學
EEM 的特徵不必是黑箱。把幾個有化學意義的激發 × 放射區域各自取平均, 就得到「看得懂」的特徵——而它們隨老化的變化,正好對應橄欖油裡真實發生的化學。
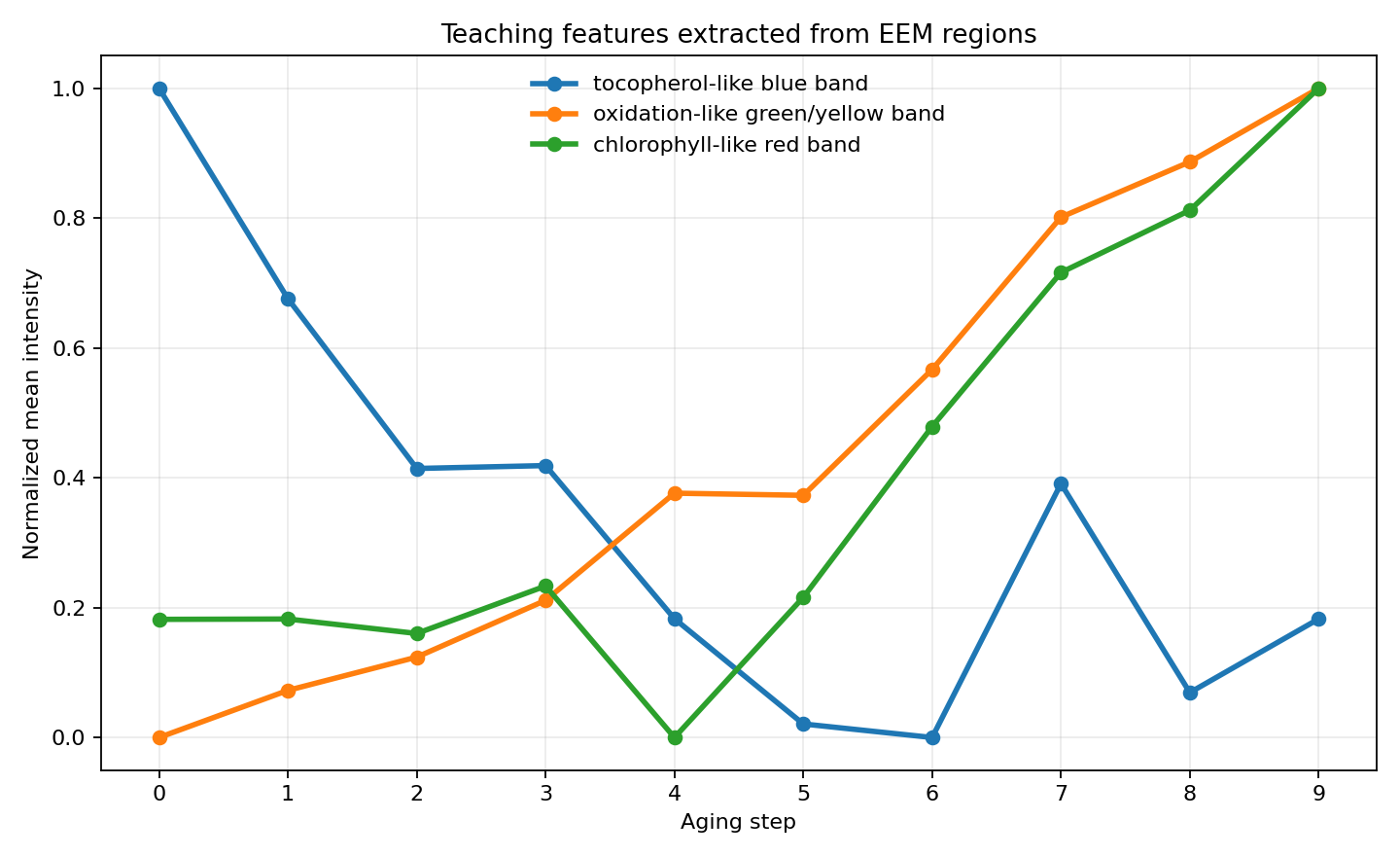
藍光區 · 生育酚類
Ex 300–340 / Em 320–380 nm。對應維生素 E 等天然抗氧化劑,老化前段被消耗而下降。綠/黃光區 · 氧化類
Ex 350–450 / Em 400–520 nm。氧化產物累積,隨老化逐步上升。紅光區 · 葉綠素類
Ex 350–460 / Em 650–750 nm。橄欖油特有色素訊號,隨老化重新分布。PCA:把上百個螢光特徵壓成幾個方向
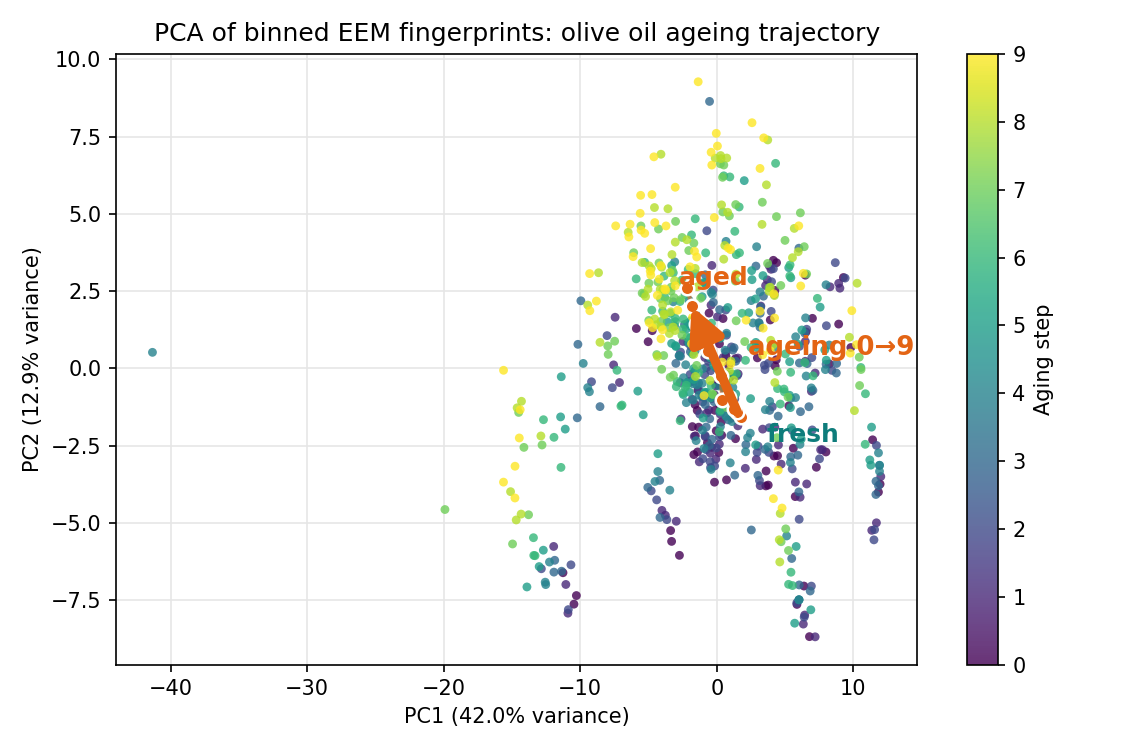
主成分分析(Principal Component Analysis)在資料最分散的方向上建立新座標軸: PC1 是變異最大的方向、PC2 與它垂直且次大……少數幾個主成分,就能描述最重要的老化結構。
分數圖:老化軌跡自己浮現
分類:用螢光指紋鑑別新鮮度
想直接回答「fresh / mid / late」,就要給模型看過老化標籤——這是監督式學習。 把 EEM 特徵當輸入、aging_class 當目標,訓練分類器並用交叉驗證誠實評估。這就是它和 PCA 的關鍵差異: PCA 只看 X,分類模型一手抓 X、一手抓類別 y。
比較多個模型,用交叉驗證選
用 Orange 的 Test & Score 同時跑 Random Forest、Logistic Regression、SVM, 以 5 折交叉驗證比較準確率;再用 Confusion Matrix 看哪些等級被搞混。
3 個老化等級
fresh / mid-aged / late-aged,由 Aging Step 分組而來。多模型比較
RF / Logistic / SVM 一起評估,挑穩定又可解釋的。Python 程式(scikit-learn)
整套分析用 numpy / pandas / scikit-learn 完成,可重現:從 EEM 矩陣萃取特徵、做 PCA、再做監督分類。
特徵萃取 — 取有化學意義的 EEM 區域平均
import numpy as np
def eem_region_mean(eem, ex, em, ex_lo, ex_hi, em_lo, em_hi):
"""取 EEM 某個激發 × 放射矩形區域的平均強度,作為可解釋特徵。"""
ex_sel = (ex >= ex_lo) & (ex < ex_hi)
em_sel = (em >= em_lo) & (em < em_hi)
return eem[np.ix_(em_sel, ex_sel)].mean()
# 三個連回化學的教學區域
tocopherol = eem_region_mean(eem, ex, em, 300, 340, 320, 380) # 生育酚(維生素E)藍光區
oxidation = eem_region_mean(eem, ex, em, 350, 450, 400, 520) # 氧化產物 綠/黃光區
chlorophyll = eem_region_mean(eem, ex, em, 350, 460, 650, 750) # 葉綠素 紅光區PCA — 主成分分析,看老化軌跡
from sklearn.preprocessing import StandardScaler
from sklearn.decomposition import PCA
X = features[bin_columns].values # 每列一個 EEM,欄為分箱螢光特徵
Xs = StandardScaler().fit_transform(X) # 標準化,讓每個 bin 公平貢獻
pca = PCA(n_components=10).fit(Xs)
scores = pca.transform(Xs) # 樣本在新軸上的位置(分數)
evr = pca.explained_variance_ratio_ * 100
# PC1 = 42.0% | PC2 = 12.9% —— 老化軌跡沿對角線浮現(與 PC2 關聯較強,r≈0.44)分類 — 鑑別 fresh / mid / late(5 折交叉驗證)
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import cross_val_predict, StratifiedKFold
from sklearn.metrics import confusion_matrix
y = features["aging_class"] # fresh / mid-aged / late-aged
clf = RandomForestClassifier(n_estimators=300, random_state=42)
yhat = cross_val_predict(clf, Xs, y,
cv=StratifiedKFold(5, shuffle=True, random_state=42))
cm = confusion_matrix(y, yhat, labels=["fresh", "mid-aged", "late-aged"])
# 看混淆矩陣:誤判幾乎都落在「相鄰等級」之間▶ 如何在本機重跑
pip install numpy pandas scipy scikit-learn matplotlib
# 1. 從 Raw_data 解析 EEM、萃取區域 + 分箱特徵 -> orange_olive_eem_features.csv
# 2. StandardScaler + PCA(10) -> 陡坡 / 分數(依 aging_step 上色)
# 3. RandomForest + 5-fold CV -> 混淆矩陣(fresh / mid / late)
# 圖輸出到 assets/plots/用 Orange Data Mining 親手拉一遍
課堂可用 Orange 的拖拉式 widget,不寫一行程式就重現上面的 PCA 與新鮮度分類。
File 指向 orange_olive_eem_features.csv,把 aging_class 設成 Target、sample_id 與 source_file 設成 Meta 即可。
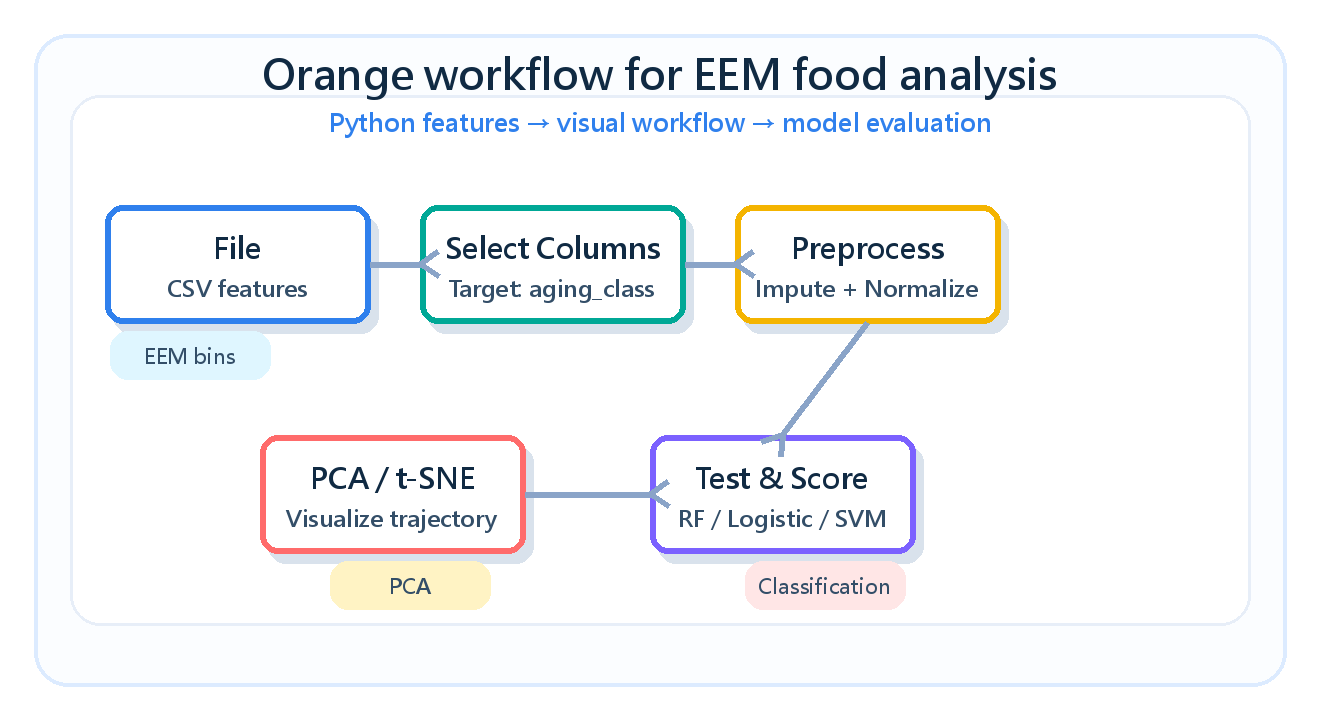
┌─ Data Table (檢視原始特徵)
│
File ────────┼─ PCA ──Transformed Data──▶ Scatter Plot ← PCA 分支(Color = aging_step)
(olive_eem │
features) └─ Select Columns ─ Preprocess ─┬─ Test & Score ──▶ Confusion Matrix
(Target = aging_class) └─(RF / Logistic / SVM 比較)| 對應概念 | Python 圖 | Orange widget |
|---|---|---|
| EEM 螢光指紋 | eem_fresh / eem_late | File → Data Table |
| 區域特徵隨老化 | feature_trends | Select Columns → Line Plot |
| 老化軌跡(依階段上色) | pca_olive_eem | PCA → Scatter Plot(Color=aging_step) |
| 新鮮度分類 + 評分 | — | Preprocess → Test & Score |
| 哪些等級被搞混 | — | Confusion Matrix |
PCA 與監督分類,一張表看懂
| 面向 | PCA | 監督分類 |
|---|---|---|
| 學習方式 | 非監督(只看 X) | 監督(用 X 與類別 y) |
| 目的 | 探索老化結構、分群、找異常 | 鑑別新鮮度(fresh / mid / late) |
| 找方向的準則 | 最大化 X 的變異 | 最小化分類錯誤、對齊類別分界 |
| 本課結果 | 老化軌跡沿對角線浮現(與 PC2 關聯較強) | RF / Logistic / SVM 比較,相鄰等級最易混 |
| 關鍵圖 | 分數圖、負荷量 | Test & Score、混淆矩陣 |
| 何時用 | 先用它「看」資料 | 確定要鑑別時用它建模 |