14 支咖啡的氣相層析指紋
氣相層析(Gas Chromatography, GC)把咖啡裡的揮發 / 半揮發成分依「滯留時間」一個個分開,輸出一條層析圖(時間 vs 訊號強度)。本資料有 14 支咖啡(標註 Arabica 8 支 / Robusta 6 支),每支量得 1.7–46 分鐘共 66451 個點。和 FTIR / NMR 不同,這份資料自帶真實品種標籤,是乾淨的監督式分類問題。
分離成分
不同成分滯留時間不同,一條層析圖 = 咖啡的揮發性化學指紋。真實標籤
每支咖啡已知品種(A / R),PLS-DA 可直接學「怎麼分」。挑戰
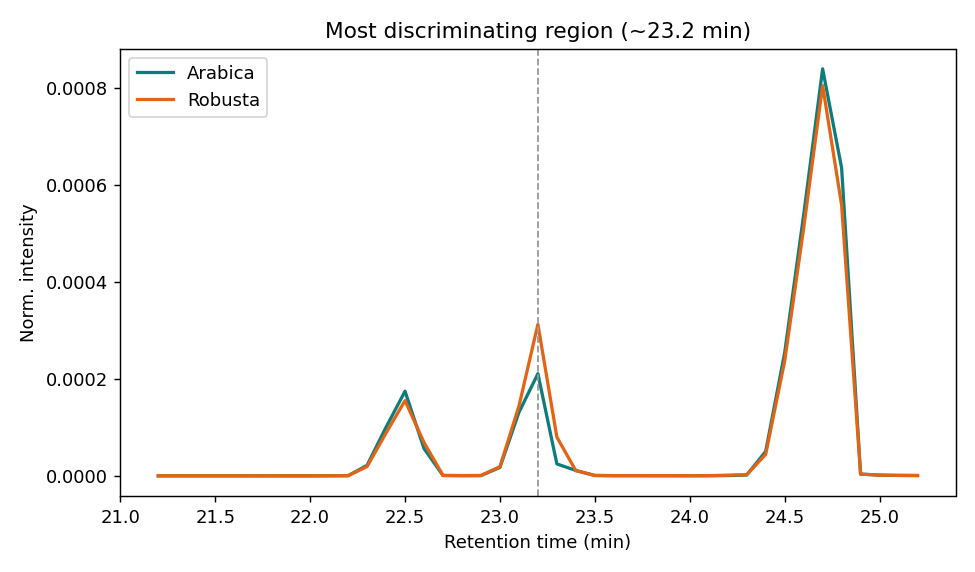
樣本只有 14 支、特徵卻有上萬個——必須降維 + 嚴格驗證,否則極易過度配適。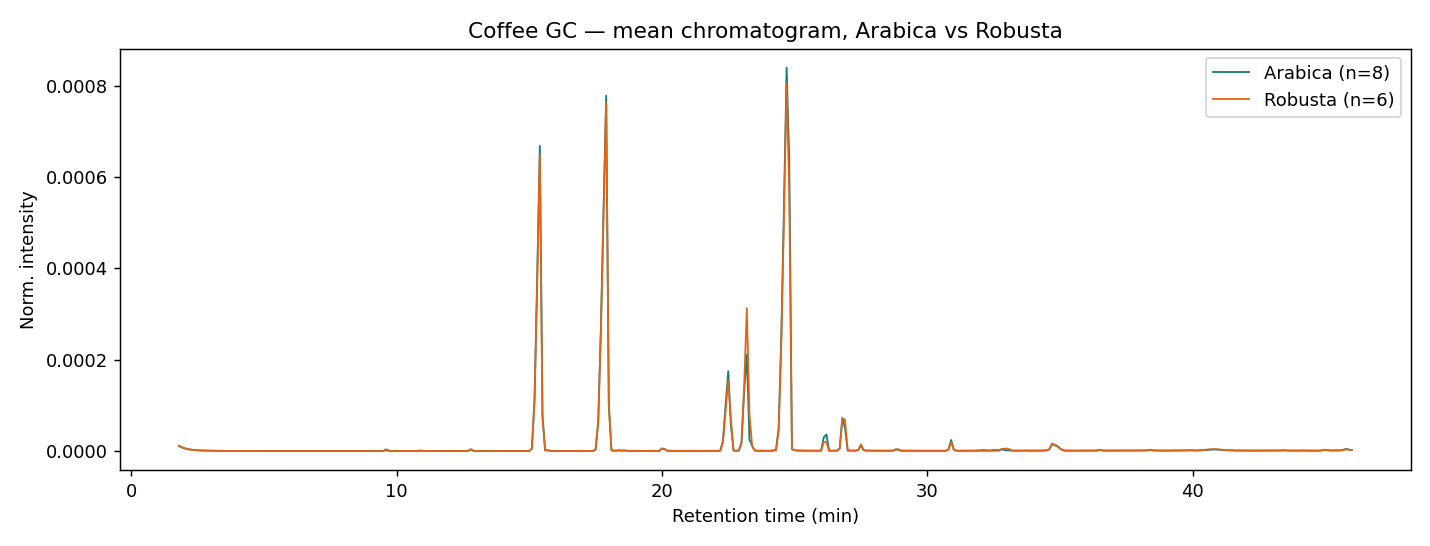
前處理:面積標準化 + 分箱
每支層析圖先做 面積標準化(總面積縮放為 1,消除進樣量差異),再 分箱(每 0.1 分鐘併成一個點 → 443 個特徵,降維去噪、緩解微小滯留時間偏移)。
| 項目 | 數值 | 說明 |
|---|---|---|
| 樣本數 | 14 | Arabica 8 / Robusta 6(c14–c27) |
| 原始時間點 | 66451 | 1.7–46 分鐘 |
| 分箱後維度 | 443 | 0.1 分鐘 / 桶 |
| 分類目標 | Arabica / Robusta | 真實品種標籤(非自訂) |
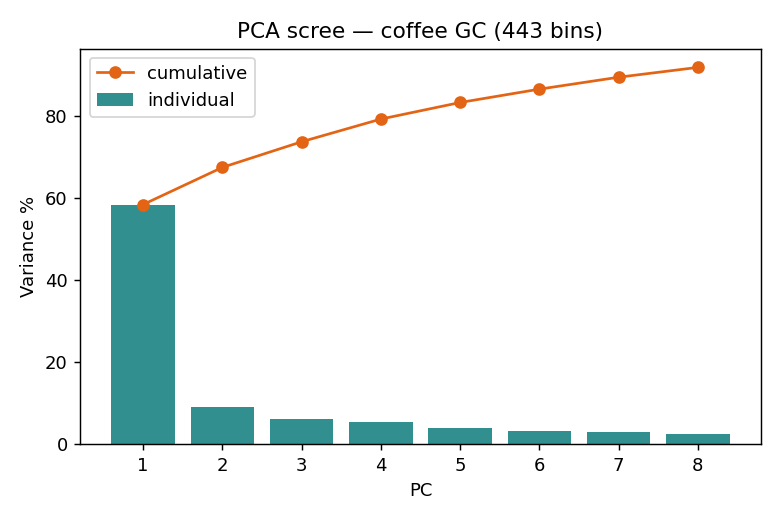
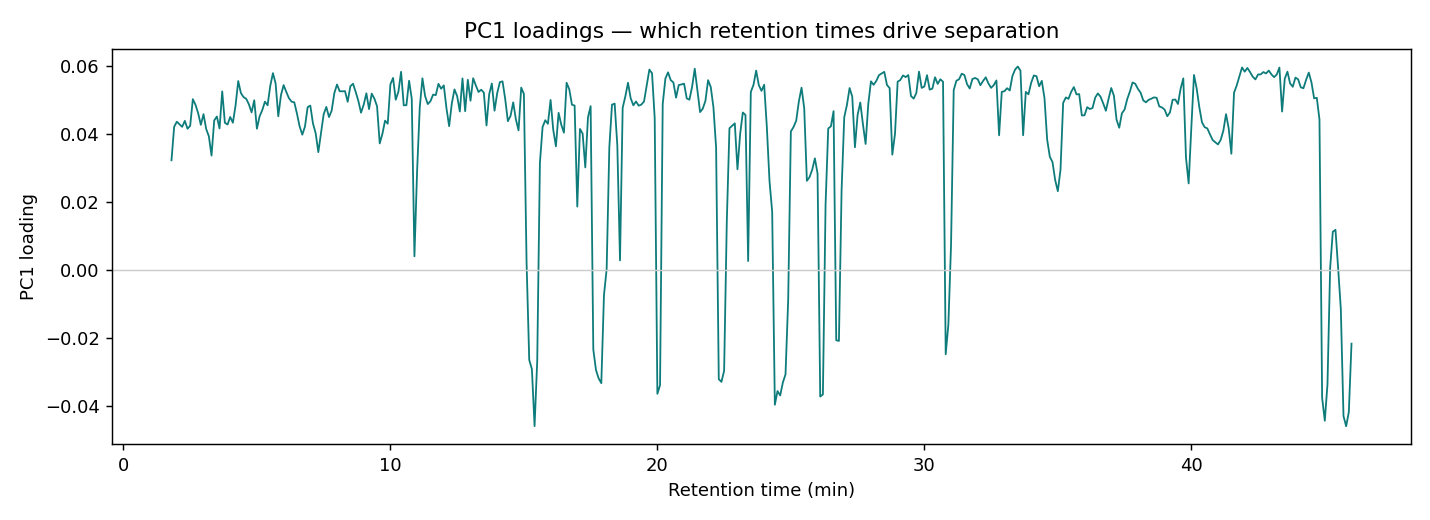
PCA:把 443 個時間點壓成幾個方向
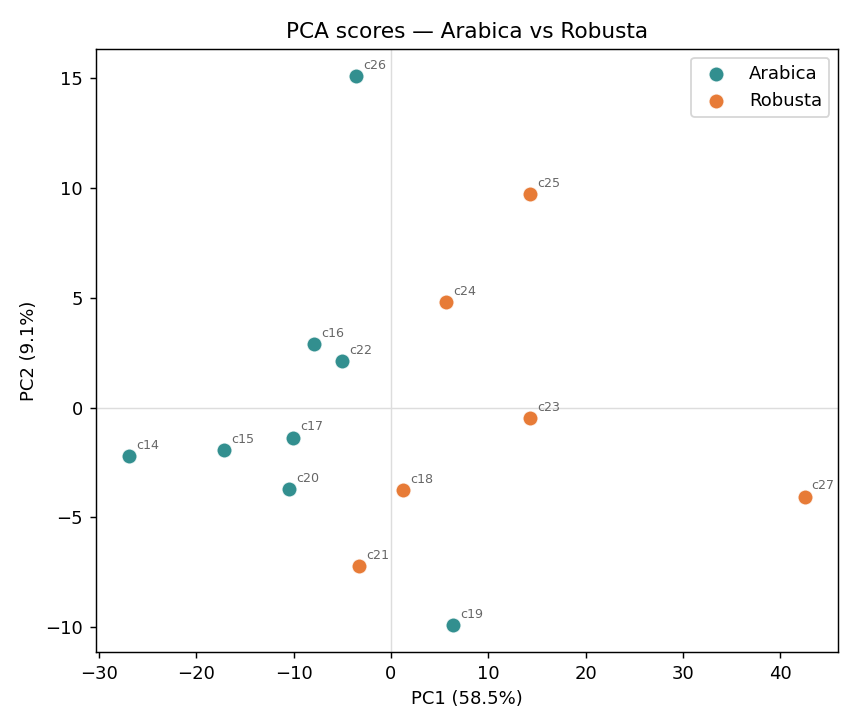
主成分分析(PCA)不看品種標籤,只在資料最分散的方向上建立新座標。少數幾個主成分就能描述整體化學結構,幫我們先「看看」這 14 支咖啡有沒有自然分群。
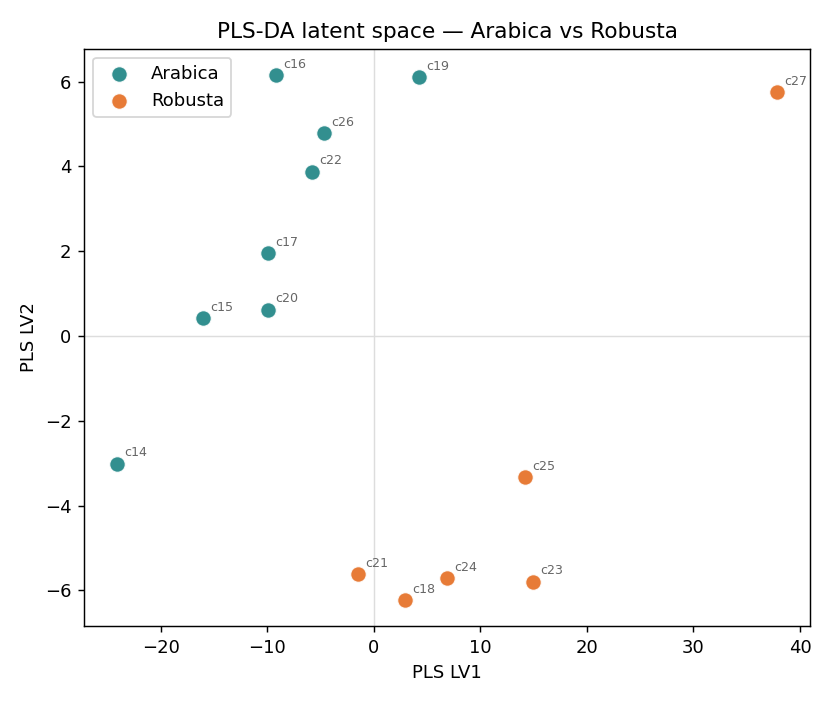
PLS-DA:鑑別 Arabica / Robusta
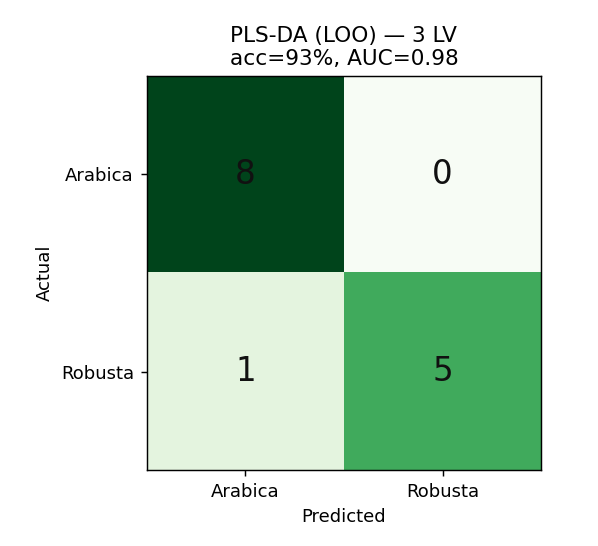
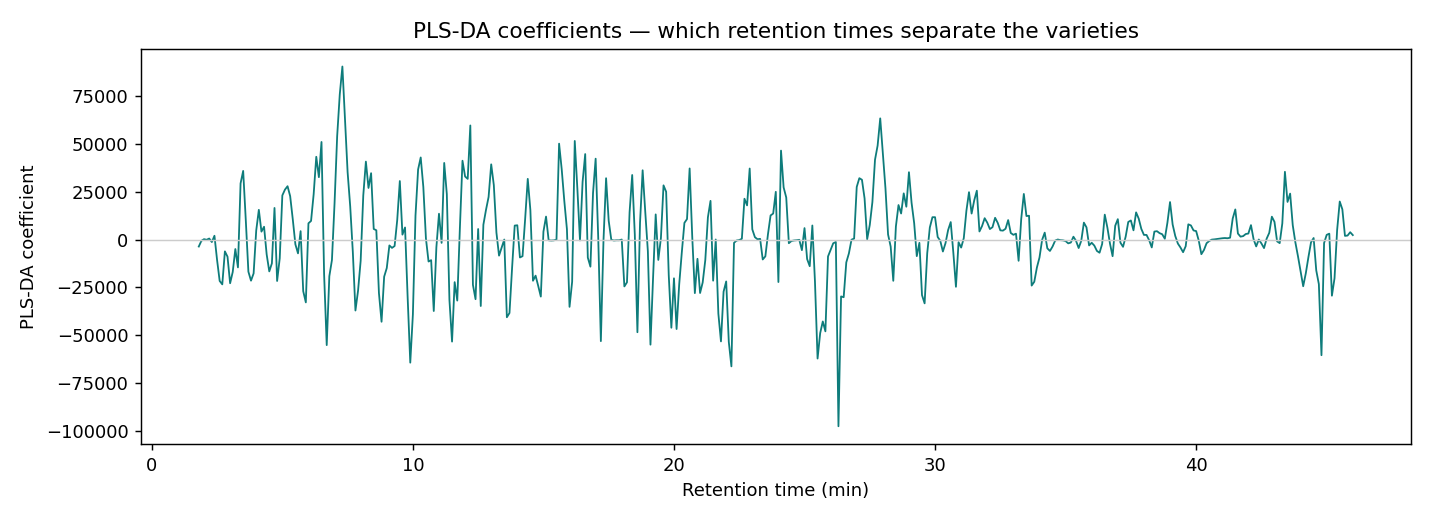
偏最小平方判別分析(PLS-DA)把類別編成 0/1,對它做 PLS 找「最能分開兩類」的方向,再以 0.5 為界判類。特別適合「特徵多(443)、樣本少(14)、又高度共線」的層析資料。
用 scikit-learn 重現
pip install pandas numpy scikit-learn matplotlib
python python/00_process.py # 讀 GC 原始檔、面積歸一、分箱(443) -> CSV / Orange
python python/01_explore.py # Arabica vs Robusta 平均層析圖 + 差異區段
python python/02_pca.py # 標準化 + PCA -> 陡坡 / 分數 / 負荷
python python/03_plsda.py # PLS-DA 品種分類(留一交叉驗證)PLS-DA 的核心(scikit-learn):
from sklearn.cross_decomposition import PLSRegression
from sklearn.model_selection import cross_val_predict, LeaveOneOut
y = (variety == "Robusta").astype(int) # 類別編成 0/1
ycv = cross_val_predict(PLSRegression(2), X, y.astype(float), cv=LeaveOneOut())
pred = (ycv > 0.5).astype(int) # 0.5 為界判類用 Orange Data Mining 拉一遍
資料檔 data/coffee_gc_orange.tab(variety 已設 class、443 個滯留時間特徵)。
- File → 開
coffee_gc_orange.tab→ 接 Data Table(14 列)。 - Preprocess → 勾 Normalize features(標準化)。
- PCA → 接 Scatter Plot,x=PC1、y=PC2、Color=
variety→ 看兩品種分開。 - 分類:把
variety設 Target → PLS 或 Logistic Regression → Test & Score(選 Leave one out)→ Confusion Matrix。
對照兩篇期刊:GC 真的分得出咖啡品種嗎?
本頁用的是「整條層析圖指紋 + PCA / PLS-DA」的示範資料(14 支)。這個結論可靠嗎?兩篇同儕審查期刊用 GC 測脂肪酸組成 的真實研究給了一致答案,並指出究竟是哪些成分在區分 Arabica 與 Robusta。
Martín 等 (2001) · Talanta
以毛細管 GC-FID 測 40 支咖啡(27 Arabica / 13 Robusta,含生豆與烘焙豆)的 10 種脂肪酸,再以 PCA + LDA 判別:
- PCA PC1 解釋 40.7%;主要判別成分為油酸 (C18:1)、次亞麻油酸 (C18:3)、亞麻油酸 (C18:2)、肉豆蔻酸 (C14:0)
- 單看「油酸 vs 次亞麻油酸」散布圖即可完全分開兩品種
- LDA 對品種辨識率 100%(生/熟四分類下,烘焙 Arabica 為 85.7%)
Romano 等 (2014) · J. Food Compos. Anal.
更進一步——不只「分類」,而是定量混合比例以防摻假。用 HRGC/FID 測脂肪酸,建立 Arabica% 校正模型:
- 判別指標:ΣMUFA、次亞麻油酸 (18:3n-3)、18:0/18:1 比值、ΣMUFA/ΣSFA
- PCA PC1 解釋 97.56%;標記與 Arabica 含量的線性迴歸 r = 0.98
- 能抓出標示與實際不符的市售混合咖啡(如標示 80%、實測約 58%)
關鍵化學:誰高誰低,兩篇一致
| 脂肪酸 | Arabica | Robusta | 判別意義 |
|---|---|---|---|
| 油酸 Oleic (C18:1) | ~7.7–8.3% | ~12.1–12.3% | Robusta 明顯較高 |
| 次亞麻油酸 Linolenic (C18:3) | ~1.4–1.5% | ~0.7–0.9% | Arabica 較高 |
| 亞麻油酸 Linoleic (C18:2) | ~43.6% | ~39.3% | 主成分、Arabica 略高 |
| 棕櫚酸 Palmitic (C16:0) | ~33–36% | ~36% | 含量最高的飽和脂肪酸 |
數值整理自 Martín 等 (2001) 與 Romano 等 (2014);脂肪酸組成在烘焙前後變化不大,是穩定的品種標記。
| 面向 | 本頁示範 | Martín 2001 | Romano 2014 |
|---|---|---|---|
| 測什麼 | 整條 GC 指紋(443 點) | 10 種脂肪酸 | 脂肪酸 + 比值標記 |
| 樣本數 | 14(示範) | 40 | 11 純品 + 多組混合 |
| 方法 | PCA + PLS-DA | PCA + LDA | PCA + 多元迴歸 |
| 目標 | 分類 A / R | 分類 A / R(+生/熟) | 定量混合比例 |
| 關鍵結果 | LOO 92.9% | LDA 100% | r = 0.98、抓出標示不符 |
引用文獻
1. Martín, M.J., Pablos, F., González, A.G., Valdenebro, M.S., León-Camacho, M. (2001). Fatty acid profiles as discriminant parameters for coffee varieties differentiation. Talanta 54(2), 291–297.
2. Romano, R., Santini, A., Le Grottaglie, L., Manzo, N., Visconti, A., Ritieni, A. (2014). Identification markers based on fatty acid composition to differentiate between roasted Arabica and Canephora (Robusta) coffee varieties in mixtures. Journal of Food Composition and Analysis 35(1), 1–9.
一條層析圖,兩個方法
PCA
非監督探索:14 支咖啡的主要差異方向,PC1 就大致對上品種。PLS-DA
監督分類:用 GC 指紋分 Arabica / Robusta,LOO 準確率 92.9%、AUC 0.98。素養
n ≪ p 易過配;用 LOO 誠實驗證,小樣本結論僅供示範。同主題搭配課程(咖啡真偽鑑別)
資料來源:使用者提供之咖啡 GC 層析資料(14 支,Arabica / Robusta;2020)。教學示範用途。